
Toolkit Walkthrough
Welcome to the Archives Unleashed Toolkit hands-on walkthrough!

The reality of any hands-on workshop is that things will break. We've tried our best to provide a robust environment that can let you walk through the basics of the Archives Unleashed Toolkit alongside us.
If you have any questions, let us know in Slack!
Table of Contents
- Installation and Use
- Extracting some Text
- Web of Links: Network Analysis
- Working with the Data
- Acknowledgements and Final Notes
Installation and Use
Got Docker?
This lesson requires that you install
Docker, and use docker-aut. We have
instructions on how to install Docker
here
, as well as instructions on how to build and use docker-aut
here.
Later in this lesson, we use the networking tool Gephi.
Make sure that Docker is running! If it isn't, you might see an error like
docker: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running? – make sure to run it (on Mac, for example, you
need to run the Docker application itself).
Make a directory in your userspace, somewhere where you can find it, on your desktop
perhaps. Call it data. In my case, I will create it on my desktop
and it will have a path like /Users/ianmilligan1/desktop/data.
Use the following command, replacing /path/to/your/data with the directory.
If you want to use your own ARC or WARC files, please put them in this
directory.
docker run --rm -it -v "/path/to/your/data:/data" aut
For example, if your files are in /Users/ianmilligan1/desktop/data you would
run the above command like:
docker run --rm -it -v "/Users/ianmilligan1/desktop/data:/data" aut
Troubleshooting Tips
The above commands are important, as they make the rest of the lesson possible!
Remember that you need to have the second :/data in the above example. This
is making a connection between the directory called "data" on my desktop with a
directory in the Docker virtual machine called "docker."
Also, if you are using Windows, you will need to provide the path as it appears
in your file system. For example: C:\Users\ianmilligan1\data.
Once you run this command, you will have to wait a few minutes while data is downloaded and AUT builds. Once it is all working, you should see:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Hello World: Our First Script
Now that we are at the prompt, let's get used to running commands. The easiest way to use the Spark Shell is to copy and paste scripts that you've written somewhere else in.
Fortunately, the Spark Shell supports this functionality!
At the scala> prompt, type the following command and press enter.
:paste
Now cut and paste the following script:
import io.archivesunleashed._
import io.archivesunleashed.udfs._
RecordLoader.loadArchives("/aut-resources/Sample-Data/*.gz", sc)
.all()
.keepValidPagesDF()
.groupBy(extractDomain($"url").alias("domain"))
.count()
.sort($"count".desc)
.show(10, false)
Let's take a moment to look at this script. It:
- begins by importing the AUT libraries;
- tells the program where it can find the data (in this case, the sample data that we have included in this Docker image);
- tells it only to keep the "valid" pages, in this case HTML data
- tells it to
ExtractDomain, or find the base domain of each URL - i.e.www.google.com/catswe are interested just in the domain, orgoogle.com; - counts them - how many times does
google.comappear in this collection, for example; - and displays a DataFrame of the top ten!
Once it is pasted in, let's run it.
You run pasted scripts by pressing ctrl + d. Try that now.
You should see:
// Exiting paste mode, now interpreting.
+-------------------------+-----+
|domain |count|
+-------------------------+-----+
|equalvoice.ca |4274 |
|liberal.ca |1968 |
|policyalternatives.ca |588 |
|greenparty.ca |535 |
|fairvote.ca |442 |
|ndp.ca |416 |
|davidsuzuki.org |348 |
|canadiancrc.com |88 |
|communist-party.ca |39 |
|ccsd.ca |22 |
+-------------------------+-----+
only showing top 10 rows
import io.archivesunleashed._
import io.archivesunleashed.udfs._
We like to use this example for two reasons:
- It is fairly simple and lets us know that AUT is working;
- and it tells us what we can expect to find in the web archives! In this case, we have a lot of the Liberal Party of Canada, Equal Voice Canada, and the Green Party of Canada.
If you loaded your own data above, you can access that directory by
substituting the directory in the loadArchives command. Try it again!
Remember to type :paste, paste the following command in, and then ctrl +
D to execute.
import io.archivesunleashed._
import io.archivesunleashed.udfs._
RecordLoader.loadArchives("/data/*.gz", sc)
.all()
.keepValidPagesDF()
.groupBy(extractDomain($"url").alias("domain"))
.count()
.sort($"count".desc)
.show(10, false)
Extracting some Text
Now that we know what we might find in a web archive, let us try extracting some text. You might want to get just the text of a given website or domain, for example.
Above we learned that the Liberal Party of Canada's website has 1,968 captures in the sample files we provided. Let's try to just extract that text.
To load this script, remember to type :paste, copy-and-paste it into the shell,
and then press ctrl + d.
import io.archivesunleashed._
import io.archivesunleashed.udfs._
val domains = Array("liberal.ca")
RecordLoader.loadArchives("/aut-resources/Sample-Data/*.gz", sc)
.webpages()
.select($"crawl_date", extractDomain($"url").alias("domain"), $"url", $"content")
.filter(hasDomains($"domain", lit(domains)))
.write.csv("/data/liberal-party-text")
If you're using your own data, that's why the domain count was key! Swap out the "liberal.ca" command above with the domain that you want to look at from your own data.
Now let's look at the ensuing data. Go to the folder you provided in the very
first startup – remember, in my case it was /users/ianmilligan1/desktop/data,
and you will now have a folder called liberal-party-text. Open up the files
with your text editor and check it out!
Ouch: Our First Error
One of the vexing parts of this interface is that it creates output directories and if the directory already exists, it comes tumbling down.
As this is one of the most common errors, let's see it and then learn how to get around it.
Try running the exact same script that you did above.
import io.archivesunleashed._
import io.archivesunleashed.udfs._
val domains = Array("liberal.ca")
RecordLoader.loadArchives("/aut-resources/Sample-Data/*.gz", sc)
.webpages()
.select($"crawl_date", extractDomain($"url").alias("domain"), $"url", $"content")
.filter(hasDomains($"domain", lit(domains)))
.write.csv("/data/liberal-party-text")
Instead of a nice crisp feeling of success, you will see a long dump of text beginning with:
20/02/06 23:43:05 WARN SparkSession$Builder: Using an existing SparkSession; some configuration may not take effect.
org.apache.spark.sql.AnalysisException: path file:/data/liberal-party-text already exists.;
To get around this, you can do two things:
- Delete the existing directory that you created;
- Change the name of the output file - to
/data/liberal-party-text-2for example.
Good luck!
Other Text Analysis Filters
Take some time to explore the various filters that you can use. Check out the documentation for some ideas.
Some options:
- Keep URL Patterns: Instead of domains, what if you wanted to have text
relating to just a certain pattern? Substitute
hasDomainsfor a command like:.filter(extractDomain($"url"), Array("(?i)http://geocities.com/EnchantedForest/.*")) - Filter by Date: What if we just wanted data from 2006? You could add the
following command after
.webpages():.filter(hasDates($"crawl_date", Array("2006"))) - Filter by Language: What if you just want French-language pages? Add
another filter:
.filter($"languages", Array("fr"))).
For example, if we just wanted the French-language Liberal pages, we would run:
import io.archivesunleashed._
import io.archivesunleashed.udfs._
val domains = Array("liberal.ca")
val languages = Array("fr")
RecordLoader.loadArchives("/aut-resources/Sample-Data/*.gz", sc)
.webpages()
.filter(hasDomains(extractDomain($"url"), lit(domains)))
.filter(hasLanguages($"language", lit(languages)))
.select($"crawl_date", extractDomain($"url").alias("domain"), $"url", $"content")
.write.csv("/data/liberal-party-french-text")
Or if we wanted to just have pages from 2006, we would run:
import io.archivesunleashed._
import io.archivesunleashed.udfs._
val dates = Array("2006")
RecordLoader.loadArchives("/aut-resources/Sample-Data/*.gz", sc)
.webpages()
.filter(hasDate($"crawl_date", lit(dates)))
.select($"crawl_date", extractDomain($"url").alias("domain"), $"url", $"content")
.write.csv("/data/2006-text")
Finally, if we want to remove the HTTP headers – let's say if we want to create
some nice word clouds – we can add a final command: RemoveHttpHeader.
import io.archivesunleashed._
import io.archivesunleashed.udfs._
RecordLoader.loadArchives("/aut-resources/Sample-Data/*.gz", sc)
.webpages()
.select($"crawl_date", extractDomain($"url").alias("domain"), $"url", $"content")
.write.csv("/data/text-no-headers")
You could now try uploading one of the plain text files using a website like Voyant Tools.
Web of Links: Network Analysis
One other thing we can do is a network analysis. By now you are probably getting good at running code.
Let's extract all of the links from the sample data and export them to a file format that the popular network analysis program Gephi can use.
import io.archivesunleashed._
import io.archivesunleashed.udfs._
import io.archivesunleashed.app._
val webgraph = RecordLoader.loadArchives("/aut-resources/Sample-Data/*.gz", sc).webgraph()
val graph = webgraph.groupBy(
$"crawl_date",
removePrefixWWW(extractDomain($"src")).as("src_domain"),
removePrefixWWW(extractDomain($"dest")).as("dest_domain"))
.count()
.filter(!($"dest_domain"===""))
.filter(!($"src_domain"===""))
.filter($"count" > 5)
.orderBy(desc("count"))
WriteGEXF(graph.collect(), "/data/links-for-gephi.gexf")
By now this should be seeming pretty straightforward! (remember to keep using
:paste to enter this code).
Working with the Data
The first step should be to work with this network diagram so you can make a beautiful visualization yourself.
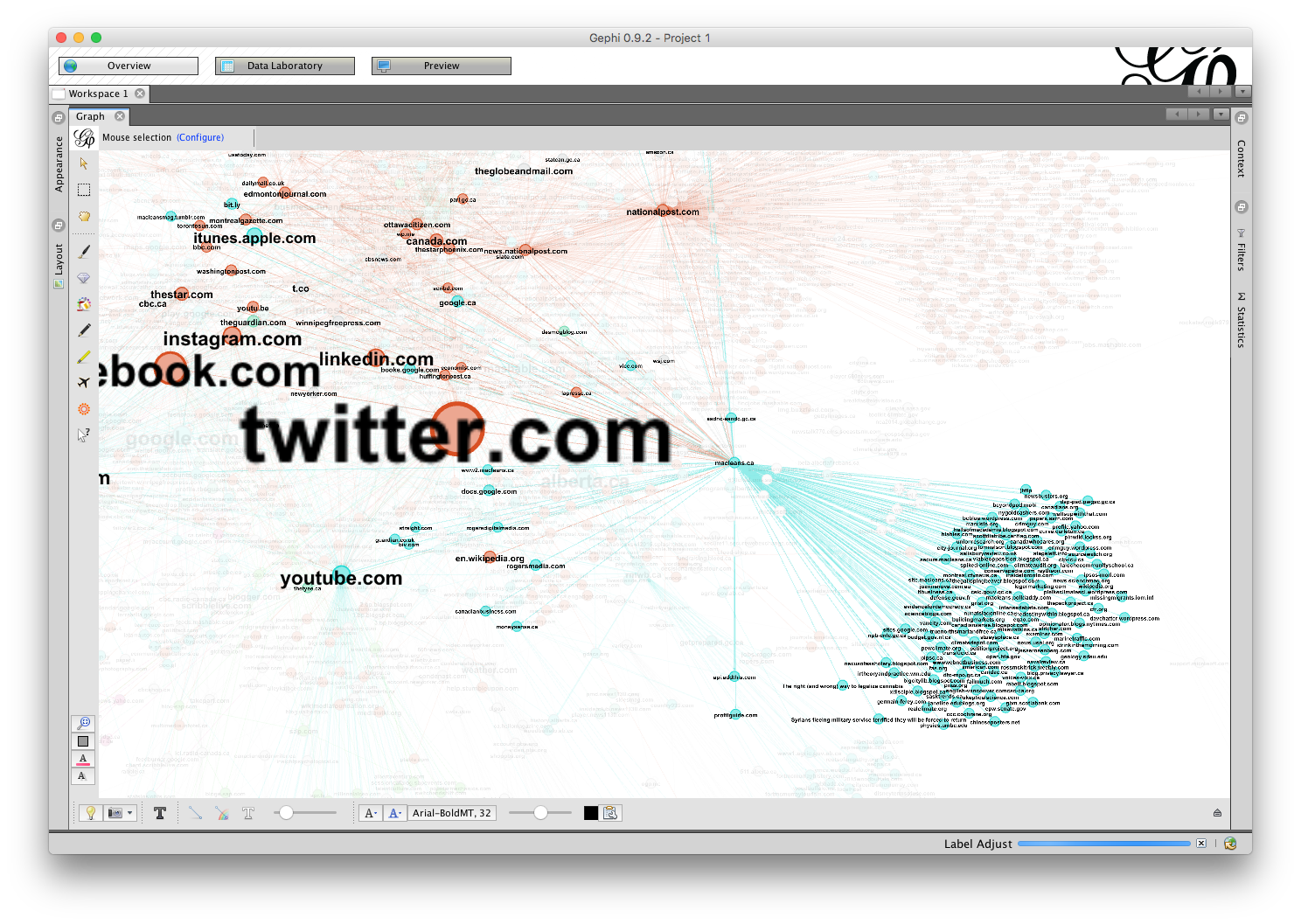
First, let's use these instructions to work with Gephi.
Secondly, we can begin to think about how” to work with the plain text file. See the following documents from our "learning guides":
- Filtering the Full-Text Derivative File: This tutorial explores the use of the "grep" command line tool to filter out dates, domains, and keywords from plain text.
- Text Analysis Part One: Beyond the Keyword Search: Using AntConc: This tutorial explores how you can explore text within a web archive using the AntConc tool.
- Text Analysis Part Two: Sentiment Analysis With the Natural Language Toolkit: This tutorial explores how you can calculate the positivity or negativity (in an emotional sense) of web archive text.
Good luck and thanks for joining us on this lesson plan.
Acknowledgements and Final Notes
The ARC and WARC file are drawn from the Canadian Political Parties & Political Interest Groups Archive-It Collection, collected by the University of Toronto. We are grateful that they've provided this material to us.
If you use their material, please cite it along the following lines:
- University of Toronto Libraries, Canadian Political Parties and Interest Groups, Archive-It Collection 227, Canadian Action Party, http://wayback.archive-it.org/227/20051004191340/http://canadianactionparty.ca/Default2.asp
You can find more information about this collection at WebArchives.ca.